

Apache Spark Explained: Architecture, Internal Flow, and Optimisation Tips

Welcome to the 249 new who have joined us since last edition!
Welcome to the newsletter on Apache Spark Whether you're a beginner or a seasoned engineer, this guide will help you understand Apache Spark from its basic concepts to its architecture, internals, and real-world applications.
Give yourself only 10 mins and then you will comfortable in Apache Spark
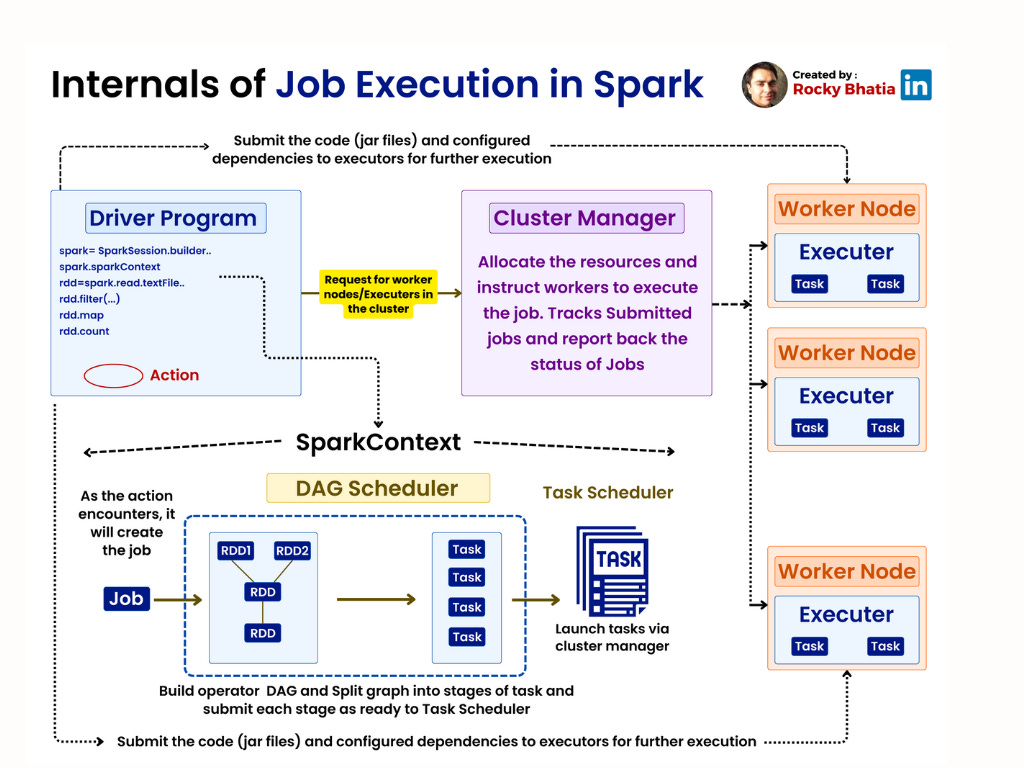
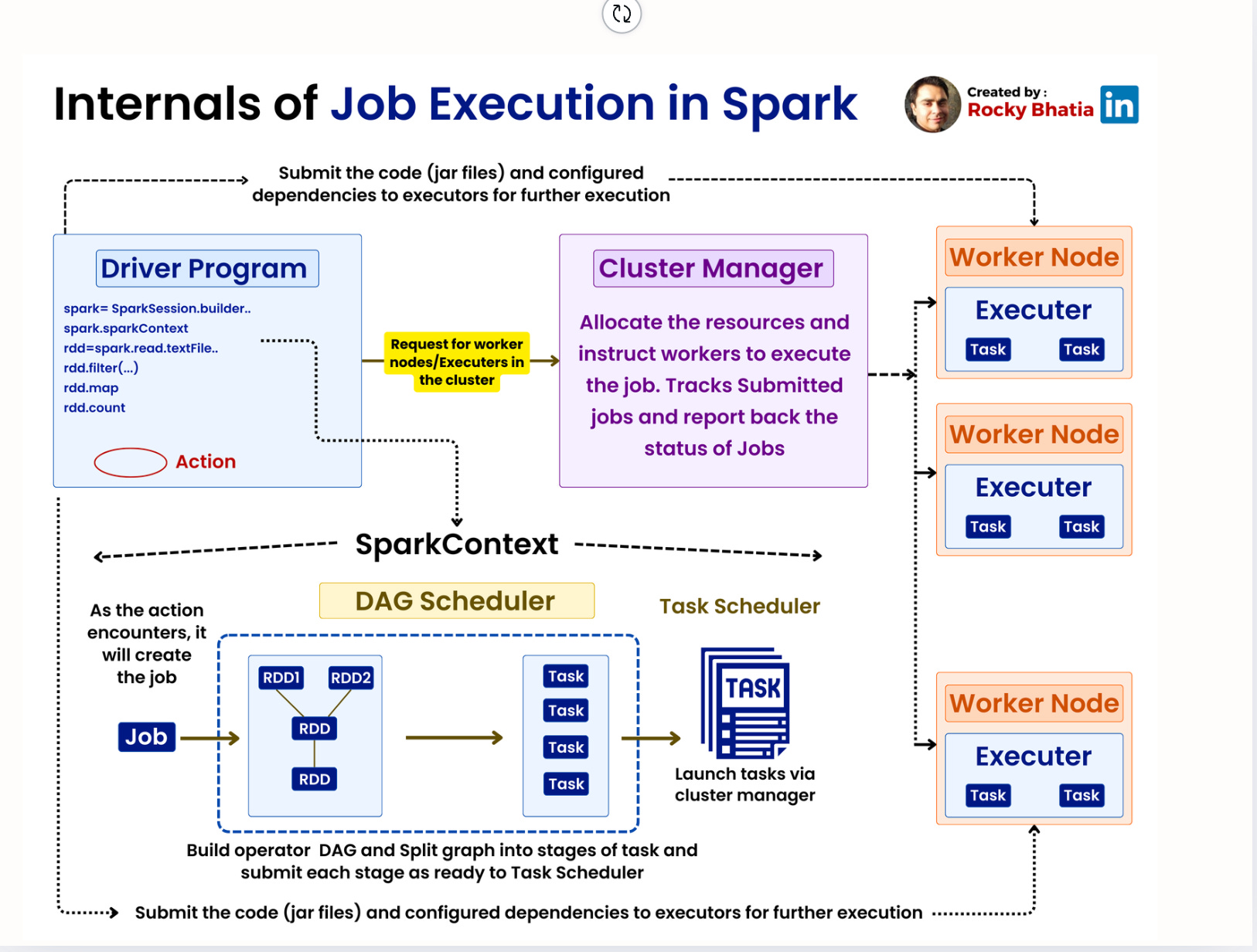
1. Getting Started with Apache Spark: A Beginner’s Guide
Spark Overview:
Spark is an open-source distributed computing system.
Built for speed, it handles both batch and stream processing.
Spark supports integration with Hadoop (HDFS, YARN), Apache Kafka, and NoSQL databases.
Key Features:
Unified Analytics Engine:
Combines batch, stream processing, and machine learning under one framework.
In-Memory Processing:
Intermediate data is stored in memory, reducing disk I/O overhead.
Fault Tolerance:
Data is distributed and fault-tolerant through lineage information (DAG).
Key Components:
RDDs (Resilient Distributed Datasets):
Low-level abstraction.
Enables fault tolerance using lineage graphs.
Operations:
Transformations: map(), filter(), flatMap(), etc.
Actions: collect(), reduce(), count(), etc.
Example 1: Creating RDDs and Performing Basic Transformations
from pyspark.sql import SparkSession # Initialize SparkSession spark = SparkSession.builder.appName("Basics").getOrCreate() # Creating an RDD data = [1, 2, 3, 4, 5] rdd = spark.sparkContext.parallelize(data) # Transformation: Filter even numbers filtered_rdd = rdd.filter(lambda x: x % 2 == 0) # Action: Collect the results result = filtered_rdd.collect() print("Filtered Data:", result)DataFrames:
High-level abstraction over RDDs with schema support.
Optimized for SQL-based operations.
Datasets:
Typed DataFrames (Scala/Java only).
Combines functional programming with SQL optimisations.
2. Apache Spark Architecture Explained
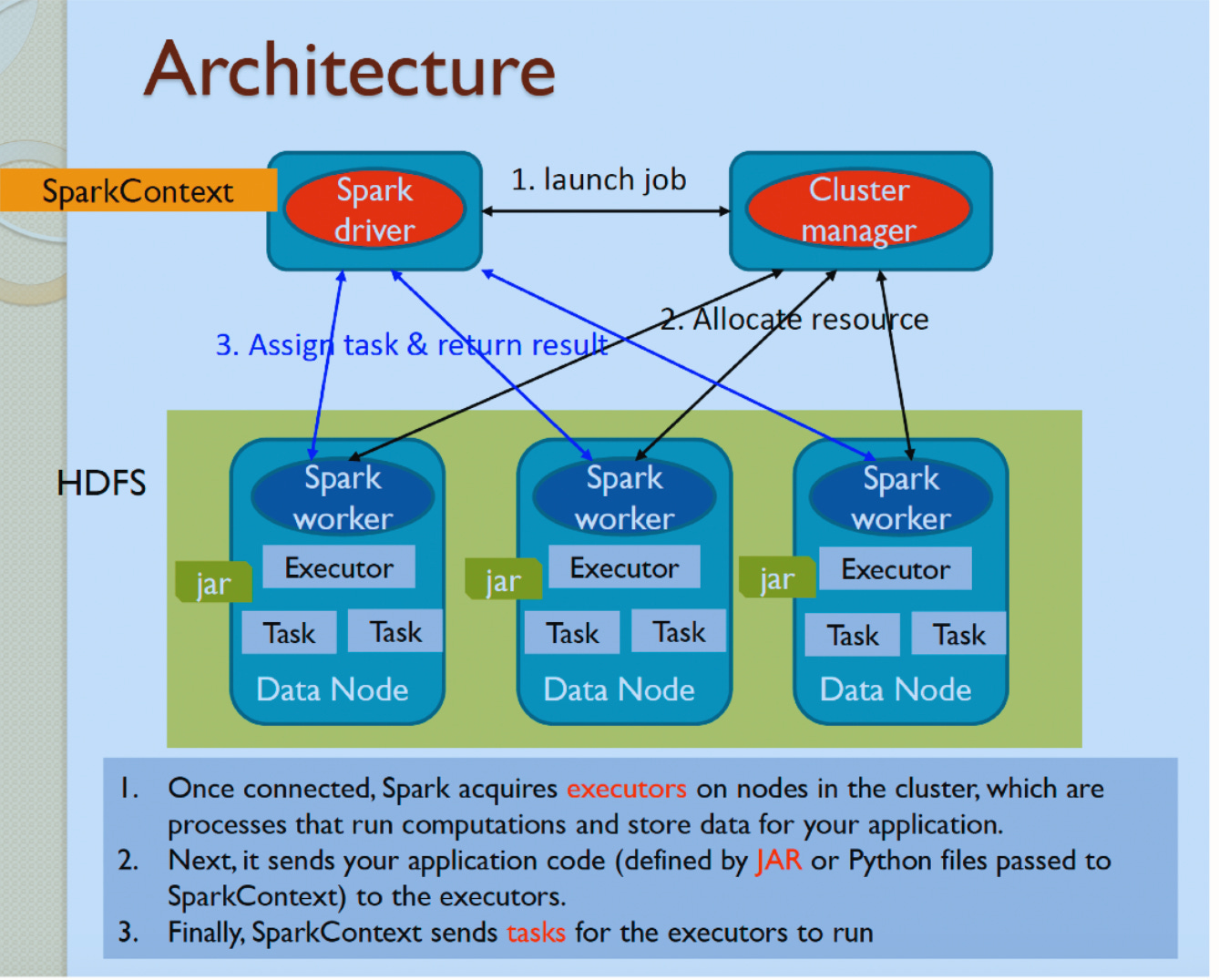
Key Components:
Driver:
Entry point for Spark applications.
Runs the user code and creates the Directed Acyclic Graph (DAG).
Tracks the state of executors and tasks.
Cluster Manager:
Allocates resources for the application.
Types:
Standalone Mode: Spark's built-in cluster manager.
YARN: Used in Hadoop-based environments.
Kubernetes: For containerized deployments.
Executors:
Run on worker nodes.
Responsible for:
Executing tasks.
Storing intermediate results in memory.
Each executor has a fixed amount of memory and CPU cores.
Architecture Diagram:
Job Execution Workflow:
Submit Application:
User code is submitted via
SparkContextorSparkSession.Build DAG:
Transformations (e.g.,
map,filter) are converted into a DAG.Example:
rdd = spark.sparkContext.parallelize([1, 2, 3, 4])
transformed_rdd = rdd.filter(lambda x: x > 2).map(lambda x: x * 2)Divide into Stages:
DAG is split into stages based on shuffle boundaries.
Execute Tasks:
Tasks are distributed to executors.
Executors run tasks in parallel, store intermediate data, and send results back to the driver.
3. How Apache Spark Works Internally: Data Processing Flow
Example Workflow: Word Count
# Example: Word Count text_rdd = spark.sparkContext.textFile("example.txt")
# Split lines into words
words_rdd = text_rdd.flatMap(lambda line: line.split(" "))
# Count each word
word_counts = words_rdd.map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# Collect and print
print(word_counts.collect())Detailed Internal Flow:

Logical Plan:
Spark builds a logical execution plan with transformations.
Example:
mapandfilterare logged but not executed immediately.
Physical Plan:
Optimizations are applied (e.g., reordering joins, predicate pushdown).
Spark chooses the most efficient way to execute the DAG.
Tasks and Stages:
Each stage is divided into tasks.
Tasks operate on partitions of data.
Shuffle Phase:
During operations like
groupByorjoin, data is redistributed across partitions.Example Shuffle Operation:
rdd = spark.sparkContext.parallelize([(1, 2), (3, 4), (3, 6)]) rdd.reduceByKey(lambda a, b: a + b).collect()4. Optimizing Apache Spark: Performance Tips
Optimizations with Code Examples:
Broadcast Joins:
Small datasets can be broadcasted to reduce shuffle costs.
Example:
small_df = spark.read.csv("small.csv")
large_df = spark.read.csv("large.csv")
result = large_df.join(broadcast(small_df), "id")Caching Data:
Cache frequently used datasets to avoid recomputation.
Example:
df = spark.read.csv("data.csv") df.cache() df.count() # Triggers cachingCopy codePartitioning:
Control partition size for better parallelism.
Example:
rdd = spark.sparkContext.parallelize(range(100), numSlices=10)Avoid Wide Transformations:
Reduce shuffle overhead by using narrow transformations like
mapPartitions.
Key Configuration Parameters:
spark.executor.memory: Memory allocated to each executor.spark.executor.cores: Number of cores per executor.spark.sql.shuffle.partitions: Number of partitions during shuffle.
5. Real-World Use Cases of Apache Spark
Use Case 1: Streaming Analytics
Example: Process real-time clickstream data from websites.
Code Snippet:
from pyspark.sql.functions import window
# Read streaming data stream_df = spark.readStream.format("socket").option("host", "localhost").option("port", 9999).load()
# Perform windowed aggregation counts = stream_df.groupBy(window("timestamp", "10 minutes")).count()
# Output results to console counts.writeStream.outputMode("complete").format("console").start().awaitTermination()Use Case 2: Machine Learning
Spark MLlib for scalable machine learning.
Example: Logistic Regression
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import VectorAssembler
# Prepare data assembler = VectorAssembler(inputCols=["feature1", "feature2"], outputCol="features")
df = assembler.transform(raw_df) # Train model lr = LogisticRegression(featuresCol="features", labelCol="label")
model = lr.fit(df)Use Case 3: Batch ETL
Transform large datasets using Spark SQL.
df = spark.read.parquet("input_data/")
transformed_df = df.filter(df["age"] > 25).groupBy("city").count() transformed_df.write.parquet("output_data/")Summary of Spark Architecture with Code and Examples:
Driver manages the lifecycle of jobs.
DAG Scheduler splits the logical plan into tasks.
Executors process data in parallel.
Optimizations include caching, partitioning, and efficient joins.
This comprehensive guide ensures in-depth coverage of Apache Spark basics, architecture, and internal execution with practical coding examples for real-world scenarios. Let me know if you'd like to dive even deeper into any specific area!
Hope you enjoyed reading this article.
If you found it valuable, hit a like and consider subscribing for more such content every week.
If you have any questions or suggestions, leave a comment.
This post is public so feel free to share it.
Subscribe for free to receive new articles every week.
Thanks for reading Rocky’s Newsletter ! Subscribe for free to receive new posts and support my work.
I actively post coding, system design and software engineering related content on
Spread the word and earn rewards!
If you enjoy my newsletter, share it with your friends and earn a one-on-one meeting with me when they subscribe. Let's grow the community together.
I hope you have a lovely day!
See you soon,
Rocky