


Kafka Crash Course: Zero to Hero in 10 Mins
Kafka Crash Course: Zero to Hero in 10 Mins

You are now 2400+ subscribers strong in a 3 weeks , thank you.
Refer just few people & Get a chance to connect 1:1 with me for career guidance
Welcome to the Kafka Crash Course! Whether you're a beginner or a seasoned engineer, this guide will help you understand Kafka from its basic concepts to its architecture, internals, and real-world applications.
Give yourself only 10 mins and then you will comfortable in Kafka
Let’s dive in!
✨1 The Basics
What is Kafka?
Apache Kafka is an open-source distributed event streaming platform capable of handling trillions of events per day. Originally developed by LinkedIn, Kafka has become the backbone of real-time data streaming applications. It’s not just a messaging system; it’s a platform for building real-time data pipelines and streaming apps, Kafka is also very popular in microservice world for any async communication
Key Terminology:
Topics: Think of topics as categories or feeds to which data records are published. In Kafka, topics are the primary means for organizing and managing data.
Producers: Producers are responsible for sending data to Kafka topics. They write data to Kafka in a continuous flow, making it available for consumption.
Consumers: Consumers read and process data from Kafka topics. They can consume data individually or as part of a group, allowing for distributed data processing.
Brokers: Kafka runs on a cluster of servers called brokers. Each broker is responsible for managing the storage and retrieval of data within the Kafka ecosystem.
Partitions: To manage large volumes of data, topics are split into partitions. Each partition can be thought of as a log where records are stored in a sequence. This division enables Kafka to scale horizontally.
Replicas: Backups of partitions to prevent data loss
Kafka operates on a publish-subscribe messaging model, where producers publish records to topics, and consumers subscribe to those topics to receive records.
Push/Pull: Producers push data, consumers pull at their own pace.
This decoupled architecture allows for flexible, scalable, and fault-tolerant data handling.
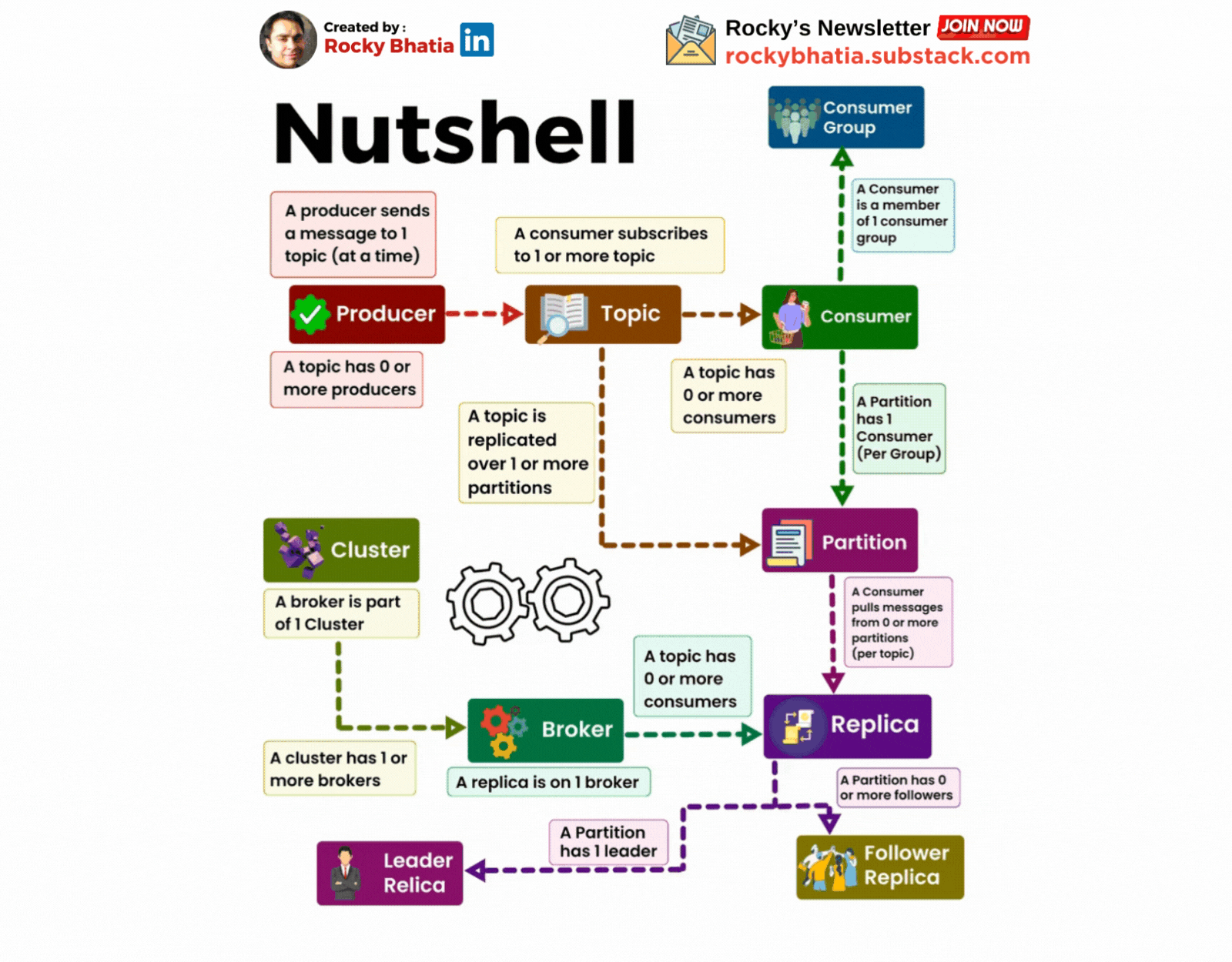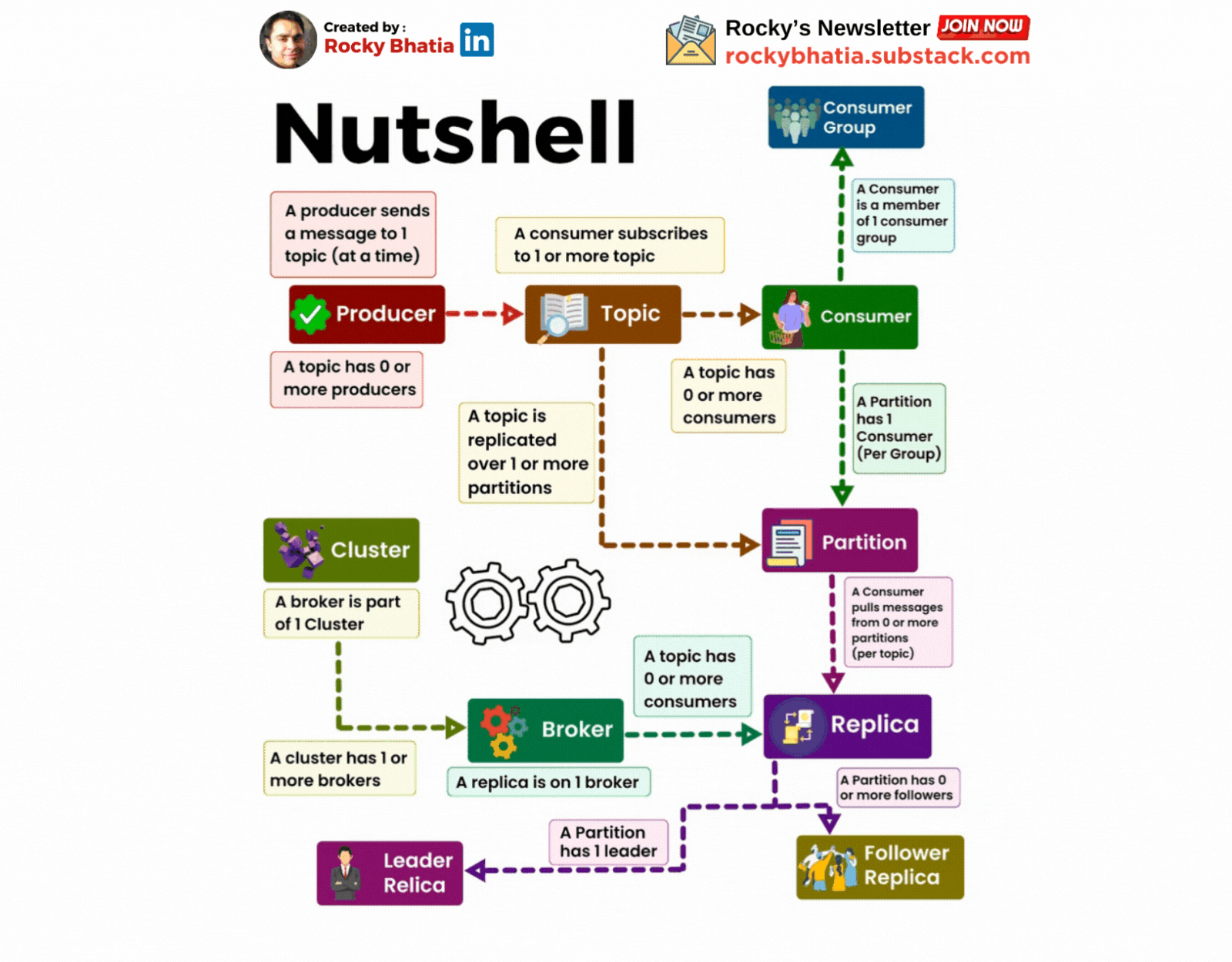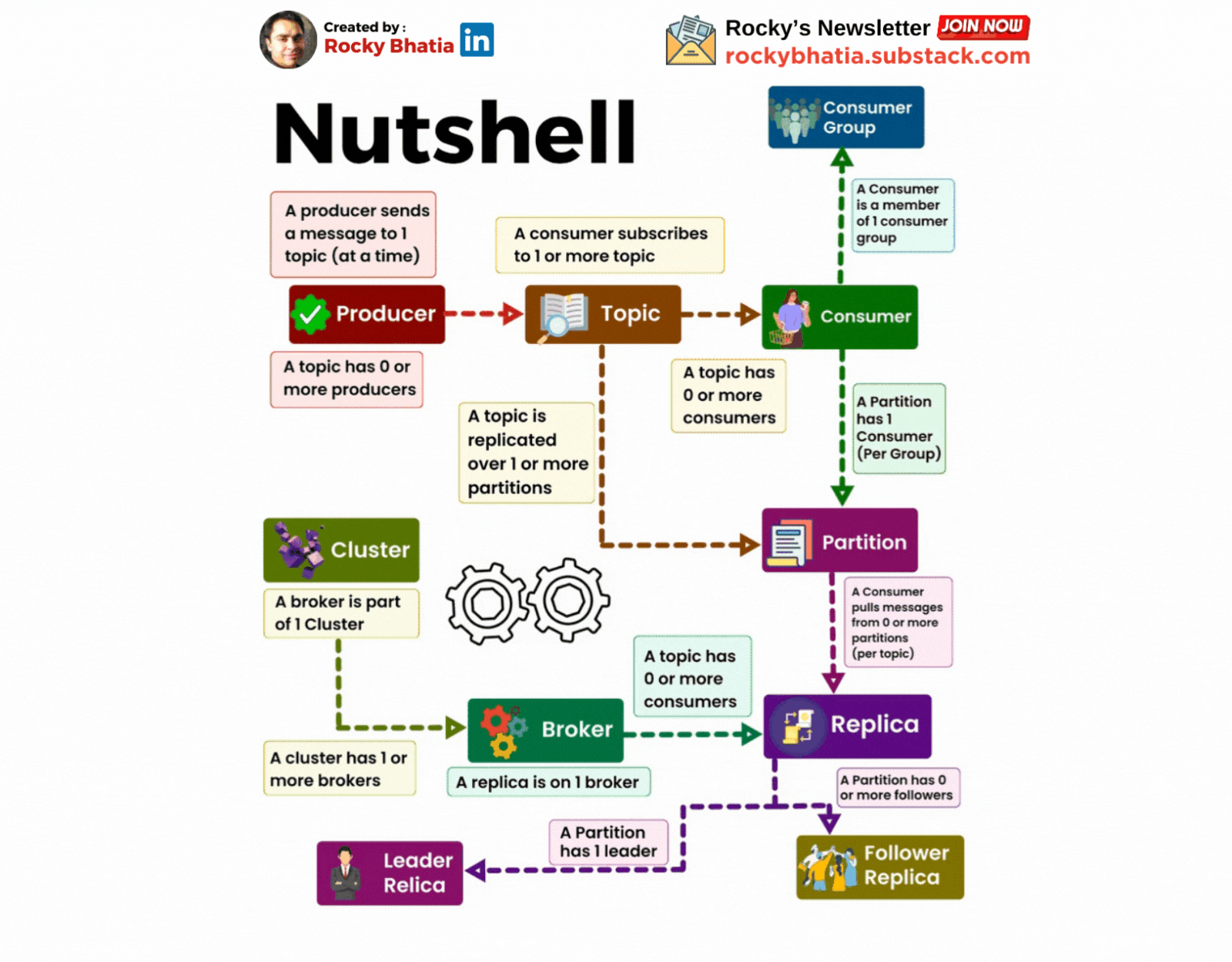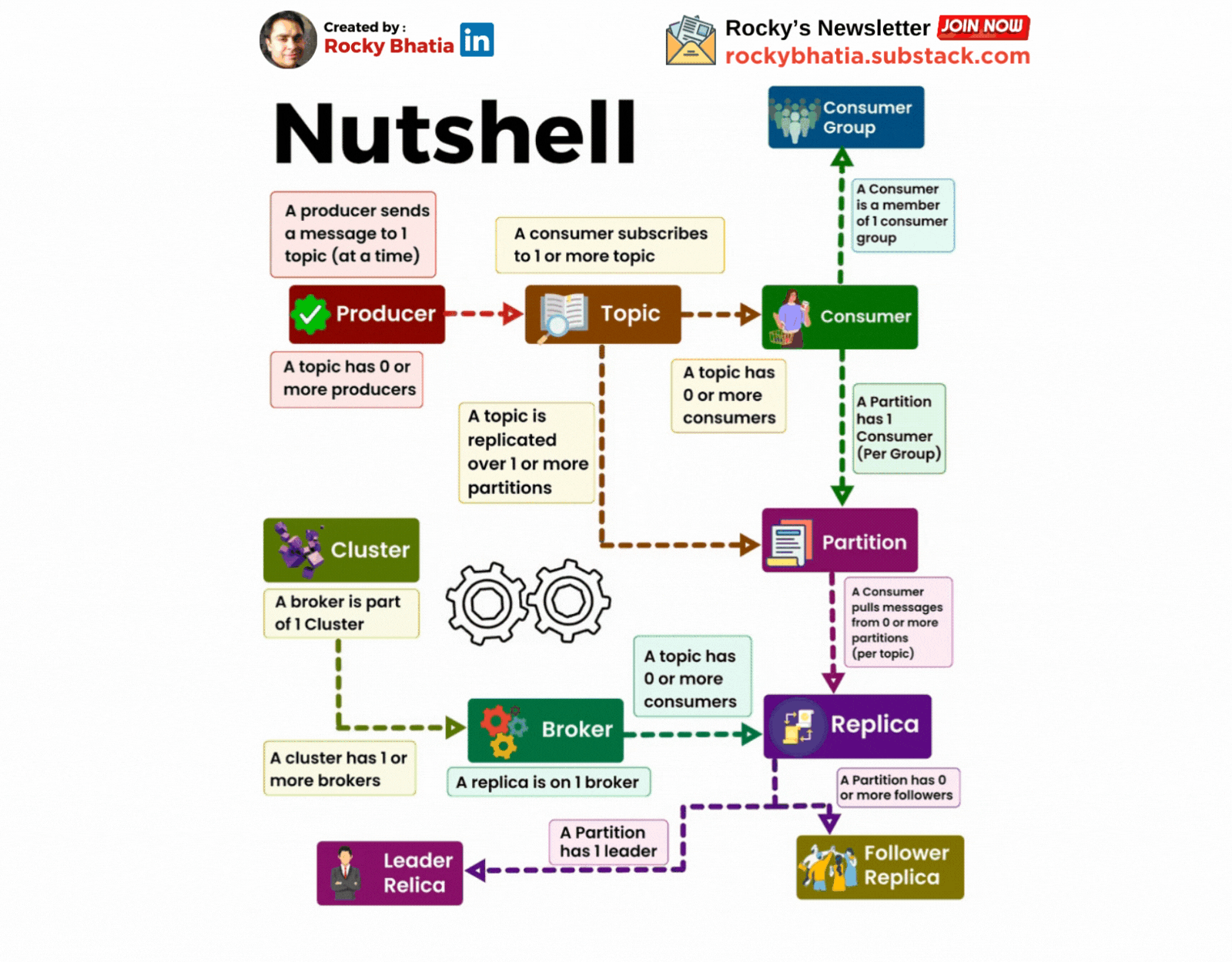
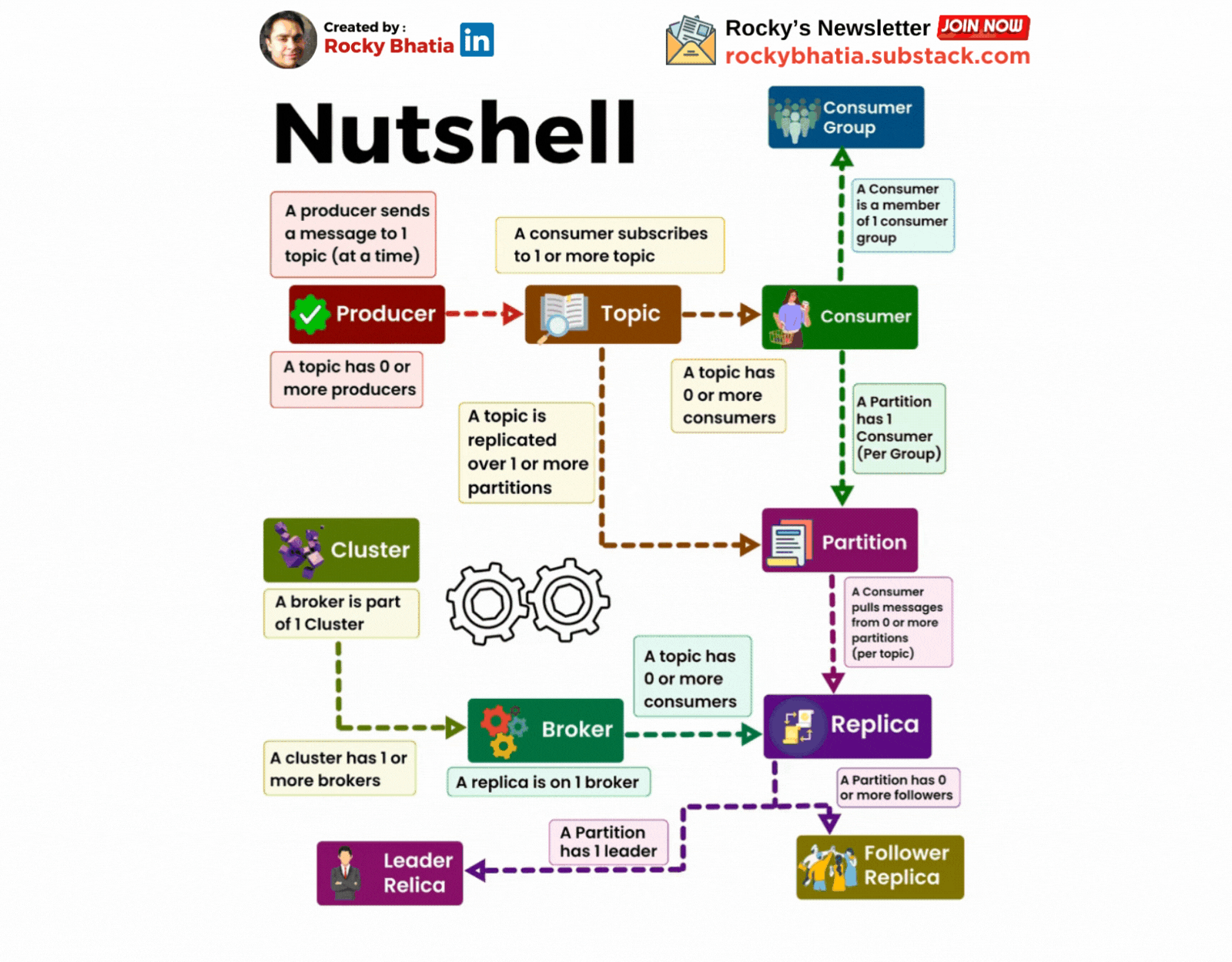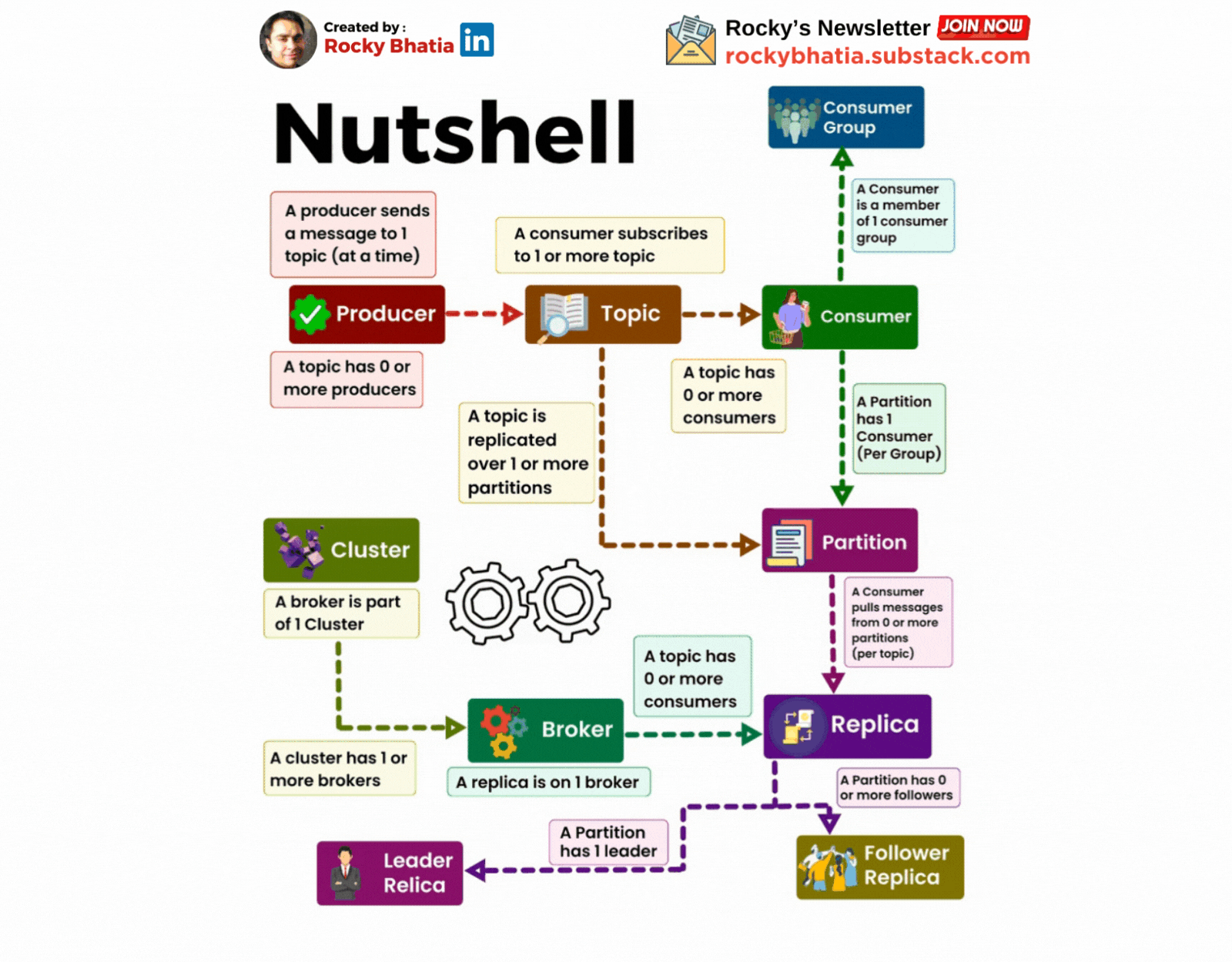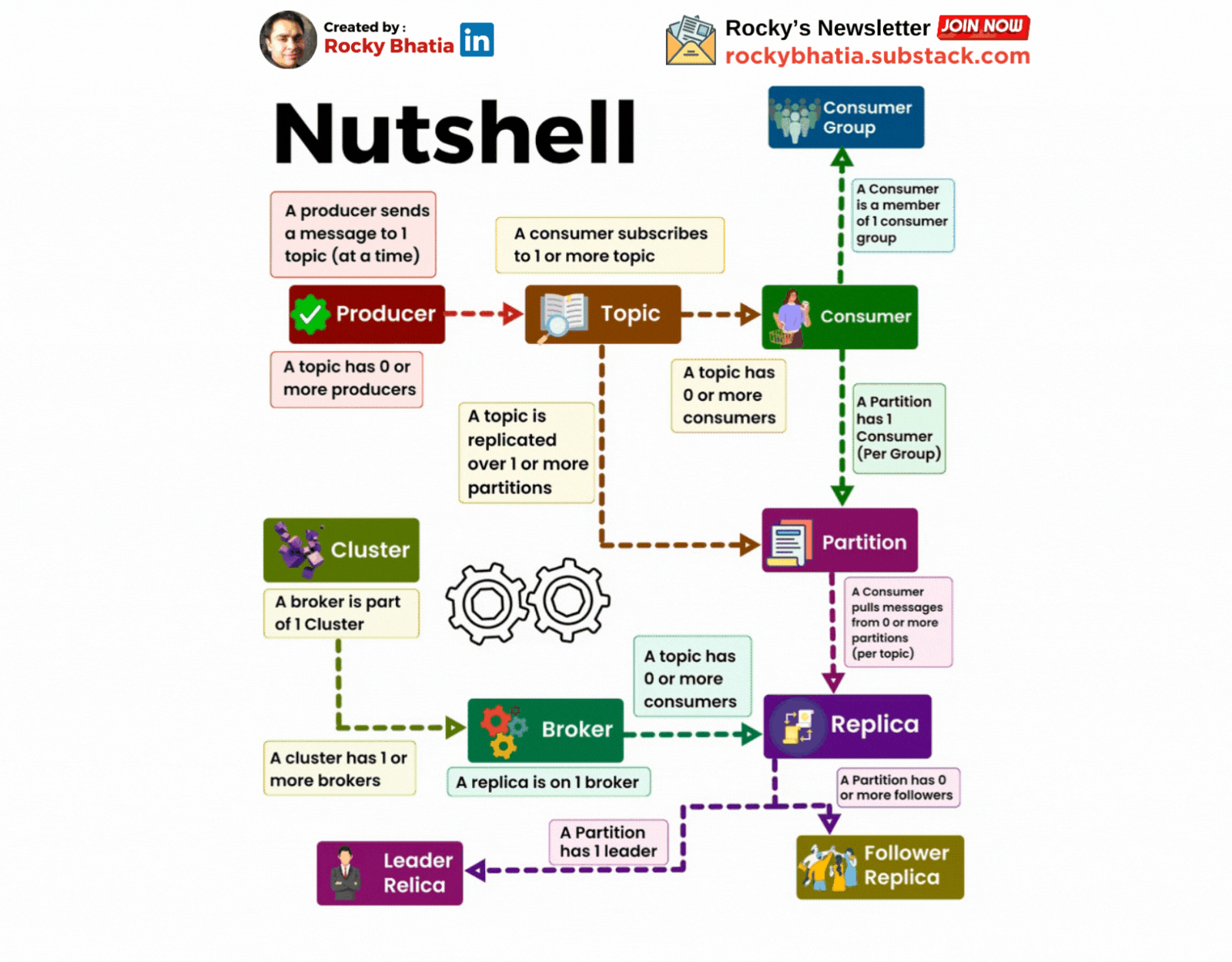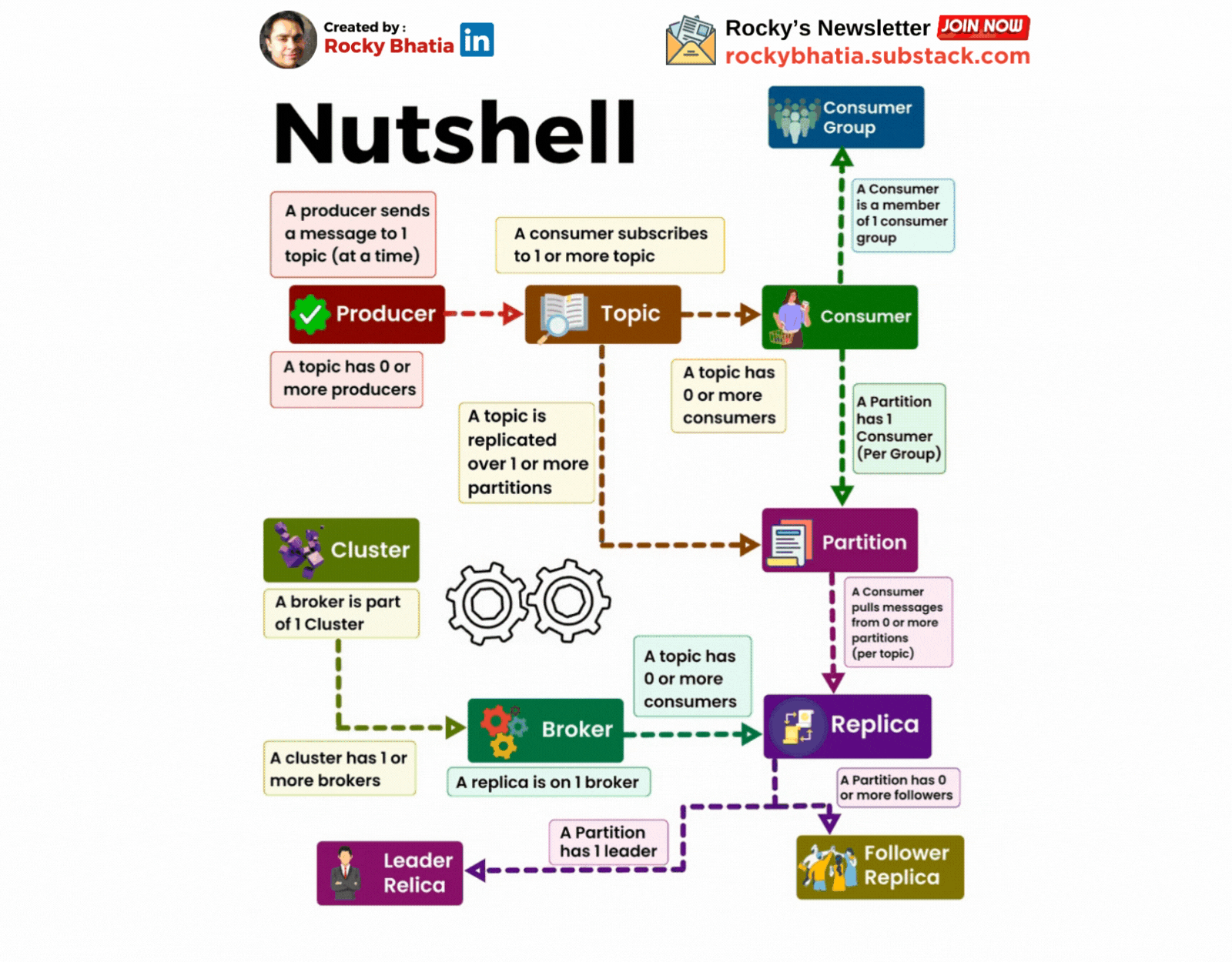
A Cluster has one or more brokers
A Kafka cluster is a distributed system composed of multiple machines (brokers). These brokers work together to store, replicate, and distribute messages.
A producer sends messages to a topic
A topic is a logical grouping of related messages. Producers send messages to specific topics. For example, a "user-activity" topic could store information about user actions on a website.
A Consumer Subscribes to a topic
Consumers subscribe to topics to receive messages. They can subscribe to one or more topics.
A Partition has one or more replicas
A replica is a copy of a partition stored on a different broker. This redundancy ensures data durability and availability.
Each Record consists of a KEY, a VALUE and a TIMESTAMP
A record is the basic unit of data in Kafka. It consists of a key, a value, and a timestamp. The key is used for partitioning and ordering messages, while the value contains the actual data. The timestamp is used for ordering and retention policies.
A Broker has zero or one replica per partition
Each broker stores at most one replica of a partition. This ensures that the data is distributed evenly across the cluster.
A topic is replicated to one or more partitions
To improve fault tolerance and performance, Kafka partitions a topic into smaller segments called partitions. Each partition is replicated across multiple brokers. This ensures that data is not lost if a broker fail
A consumer is a member of a CONSUMER GROUP
Consumers are grouped into consumer groups. This allows multiple consumers to share the workload of processing messages from a topic. Each consumer group can only have one consumer per partition.
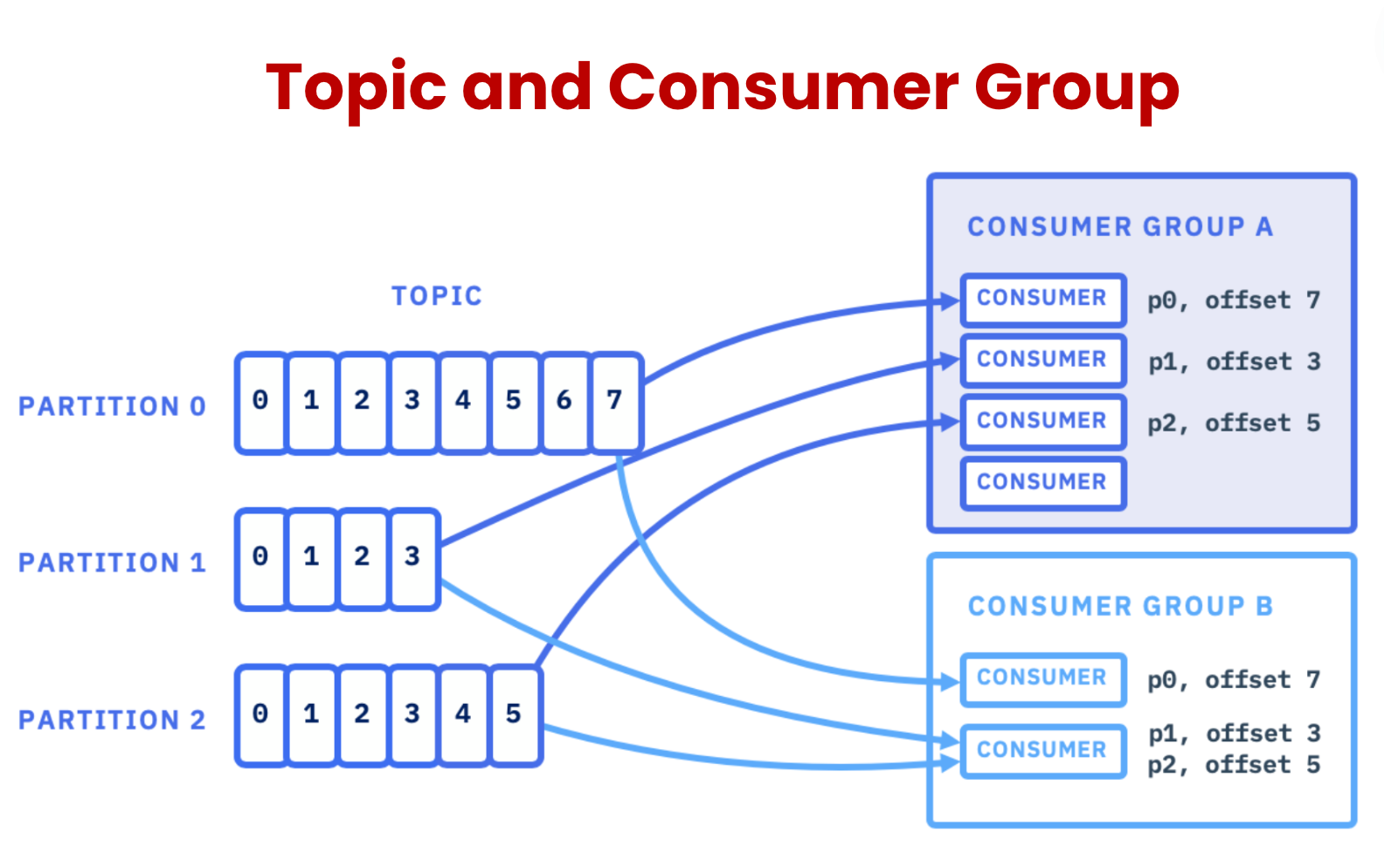
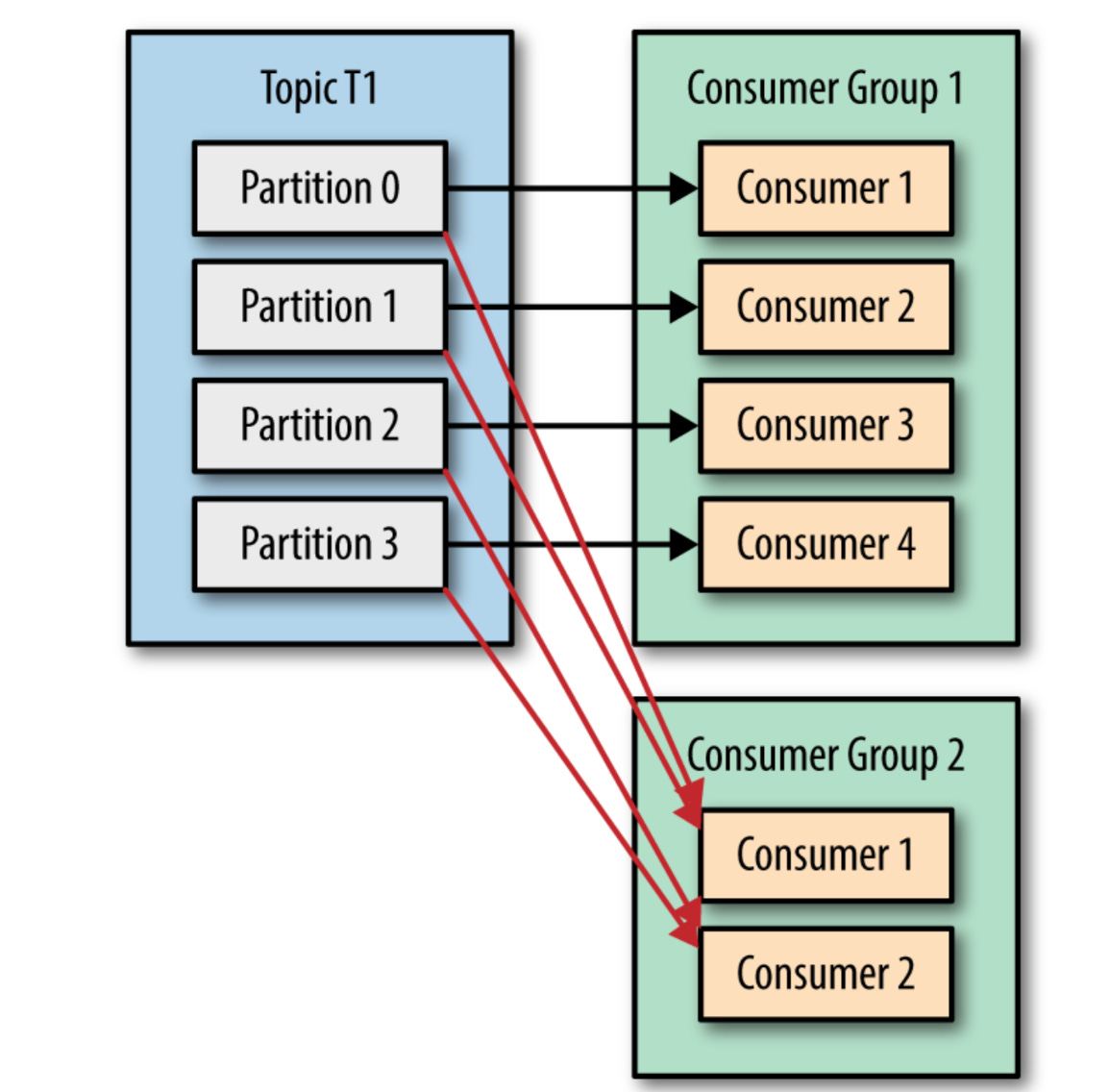
A Partition has one consumer per group
To ensure that each message is processed only once, Kafka assigns only one consumer from a consumer group to each partition.
An OFFSET is the number assigned to a record in a partition
The offset is a unique identifier for a record within a partition. Consumers use offsets to keep track of their progress and avoid processing the same message multiple times.
A Kafka Cluster maintains a PARTITIONED LOG
Kafka stores messages in a partitioned log. This log is distributed across the brokers in the cluster and is highly durable and scalable
2. 🛠️ Kafka Architecture
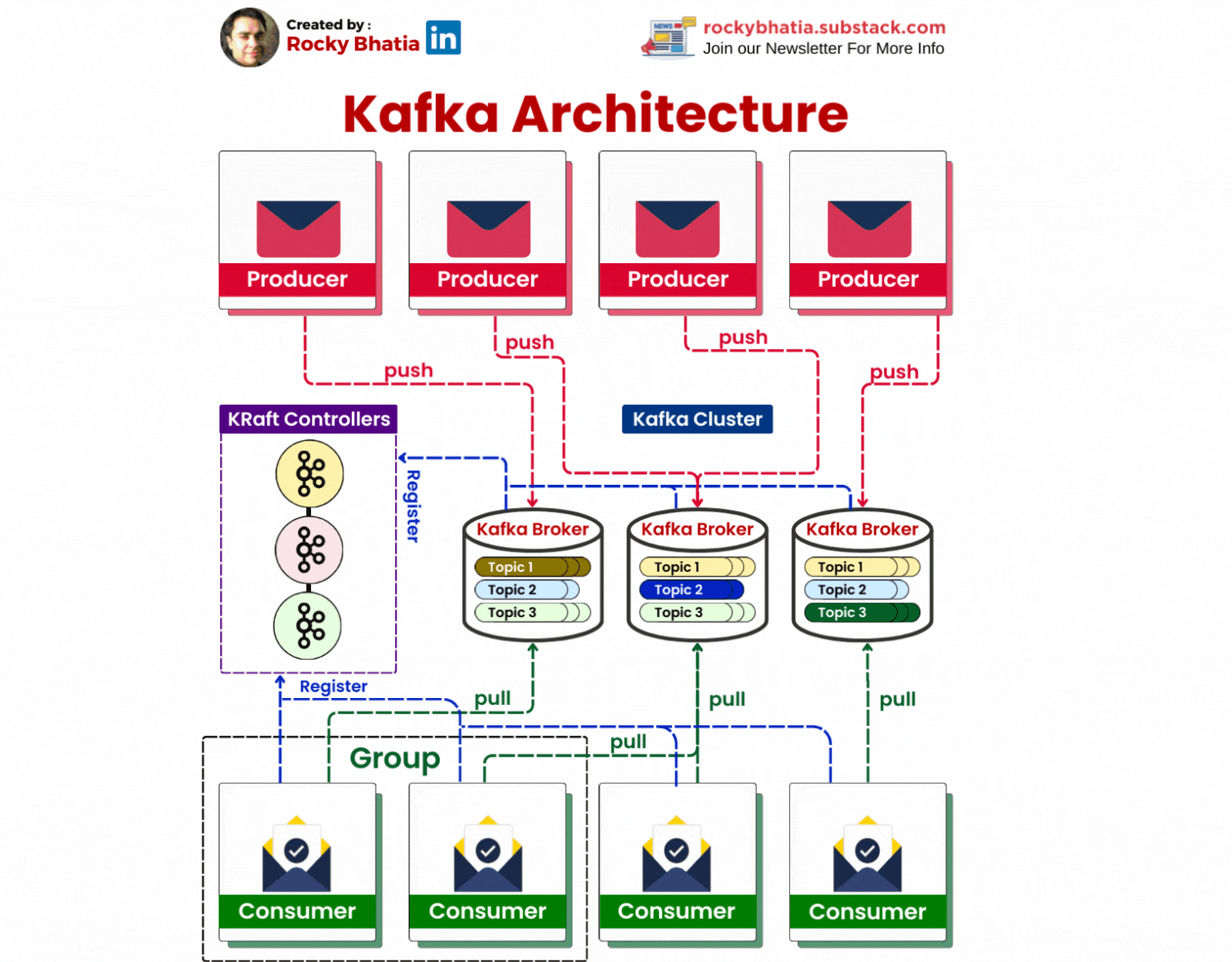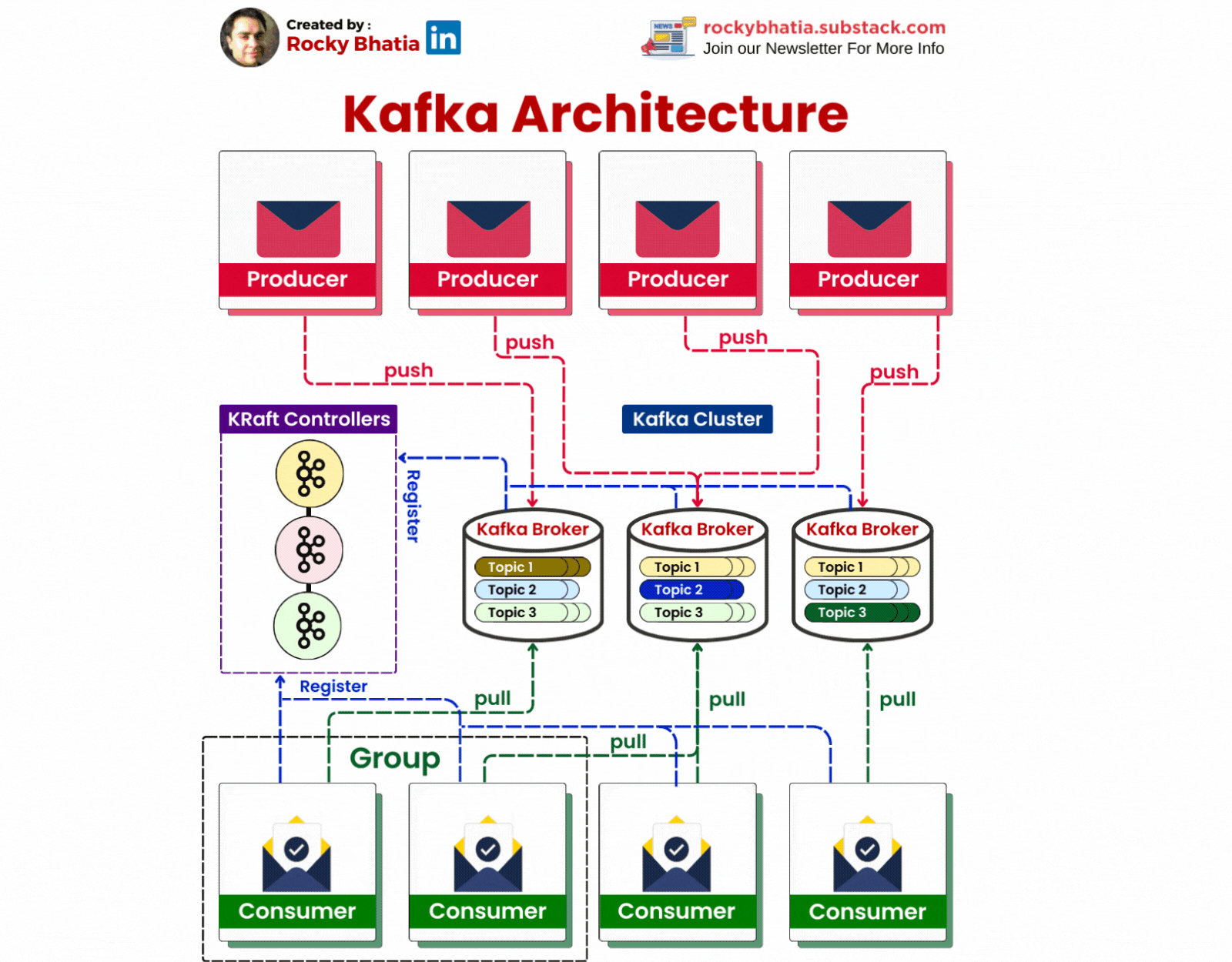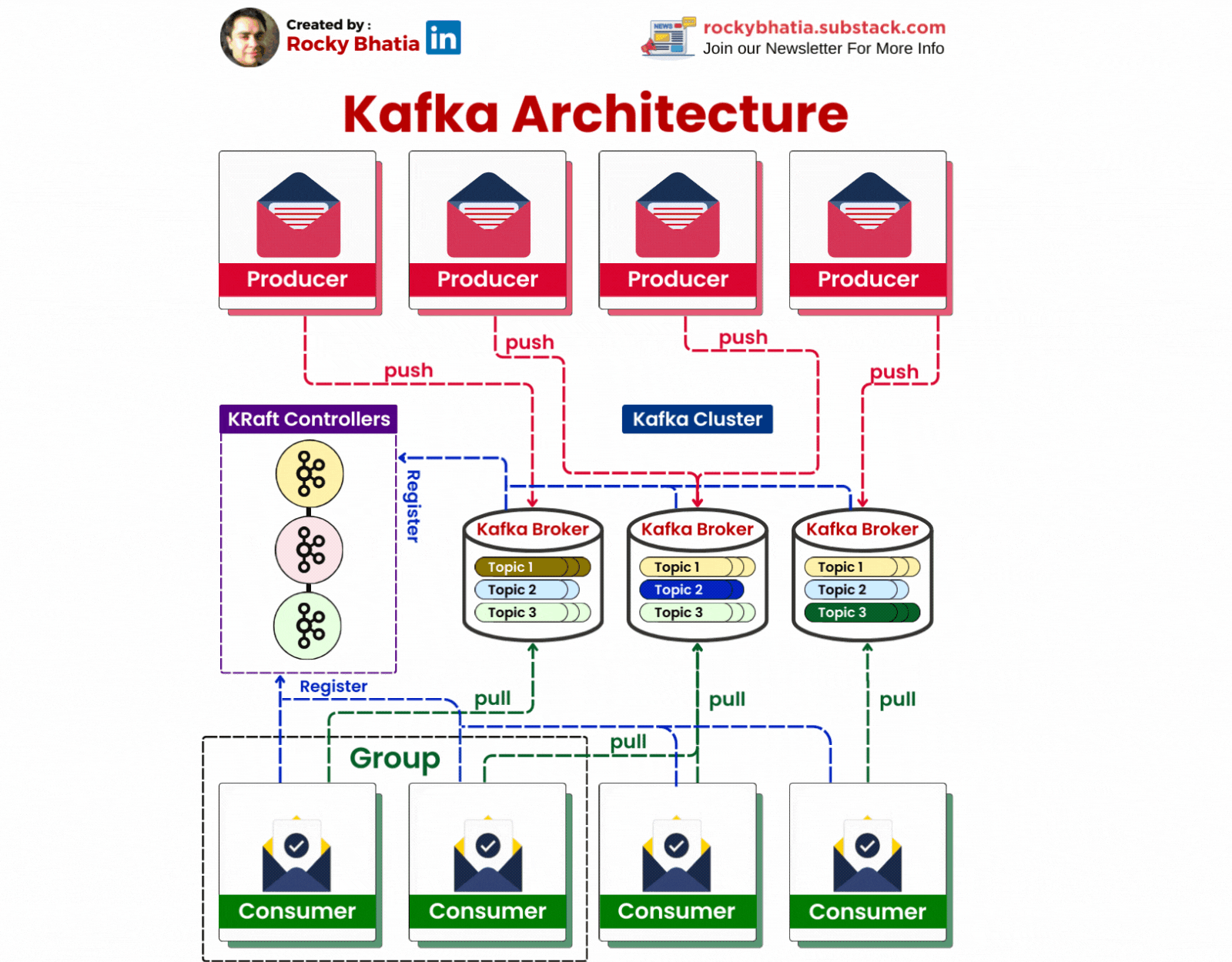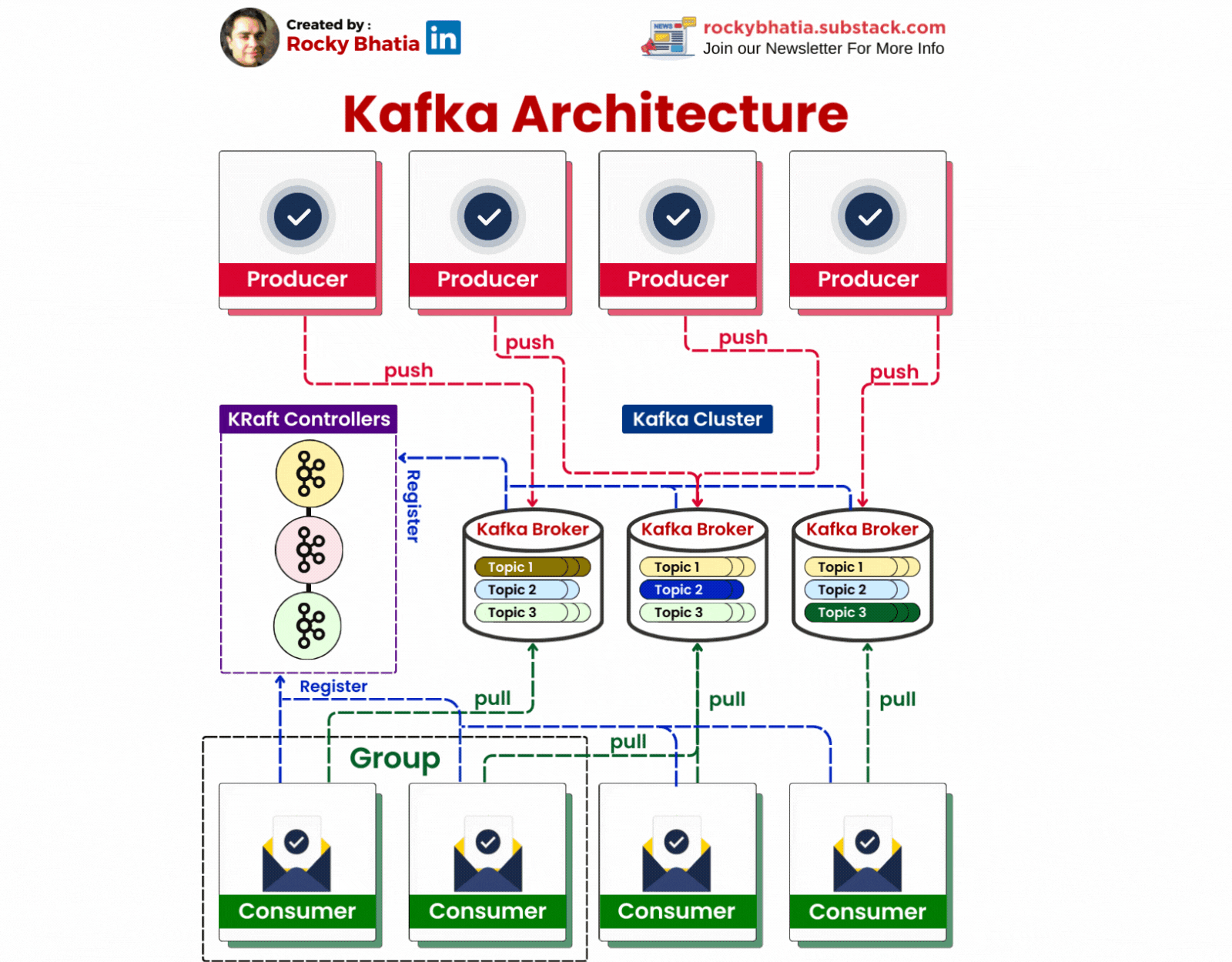
Kafka Producer
Producers: Producers are responsible for sending data to Kafka topics. They write data to Kafka in a continuous flow, making it available for consumption.
Producer Workflow:
Create Producer Instance: The producer client is initialized, providing necessary configuration parameters like bootstrap servers, topic name, and serialization format.
Produce Message: The producer creates a message object, setting the key and value.
Send Message: The producer sends the message to the Kafka cluster, specifying the topic and optionally the partition.
Handle Acknowledgements: The producer can configure the level of acknowledgement required from the broker nodes. This can range from none to all replicas, affecting reliability and performance.
Consumers: Consumers read and process data from Kafka topics. They can consume data individually or as part of a group, allowing for distributed data processing.
Consumer Workflow:
Create Consumer Instance: The consumer client is initialized, providing necessary configuration parameters like bootstrap servers, group ID, topic subscriptions, and offset management strategy.
Subscribe to Topics: The consumer subscribes to the desired topics.
Consume Messages: The consumer receives messages from the Kafka cluster, processing them as they arrive.
Commit Offsets: The consumer commits the offsets of the messages it has processed to ensure that it doesn't consume the same messages again in case of restarts or failures.
Kafka Clusters:
At the heart of Kafka is its cluster architecture. A Kafka cluster consists of multiple brokers, each of which manages one or more partitions of a topic. This distributed nature allows Kafka to achieve high availability and scalability. When data is produced, it is distributed across these brokers, ensuring that no single point of failure exists.
Topic Partitioning:
Partitioning is Kafka's secret sauce for scalability and high throughput. By splitting a topic into multiple partitions, Kafka allows for parallel processing of data. Each partition can be stored on a different broker, and consumers can read from multiple partitions simultaneously, significantly increasing the speed and efficiency of data processing.
Replication and Fault Tolerance:
To ensure data reliability, Kafka implements replication. Each partition is replicated across multiple brokers, and one of these replicas acts as the leader. The leader handles all reads and writes for that partition, while the followers replicate the data. If the leader fails, a follower automatically takes over, ensuring uninterrupted service.
Zookeeper’s Role:
Zookeeper is an integral part of Kafka’s architecture. It keeps track of the Kafka brokers, topics, partitions, and their states. Zookeeper also helps in leader election for partitions and manages configuration settings. Though Kafka has been moving towards replacing Zookeeper with its own internal quorum-based system, Zookeeper remains a key component in many Kafka deployments today.
3. Kafka Internals: Peeking Under the Hood
Log-based Storage:
Kafka’s data storage model is log-based, meaning it stores records in a continuous sequence in a log file. Each partition in Kafka corresponds to a single log, and records are appended to the end of this log. This design allows Kafka to provide high throughput with minimal latency. Kafka’s use of a write-ahead log ensures that data is reliably stored before being made available to consumers.
Kafka Delivery Semantic
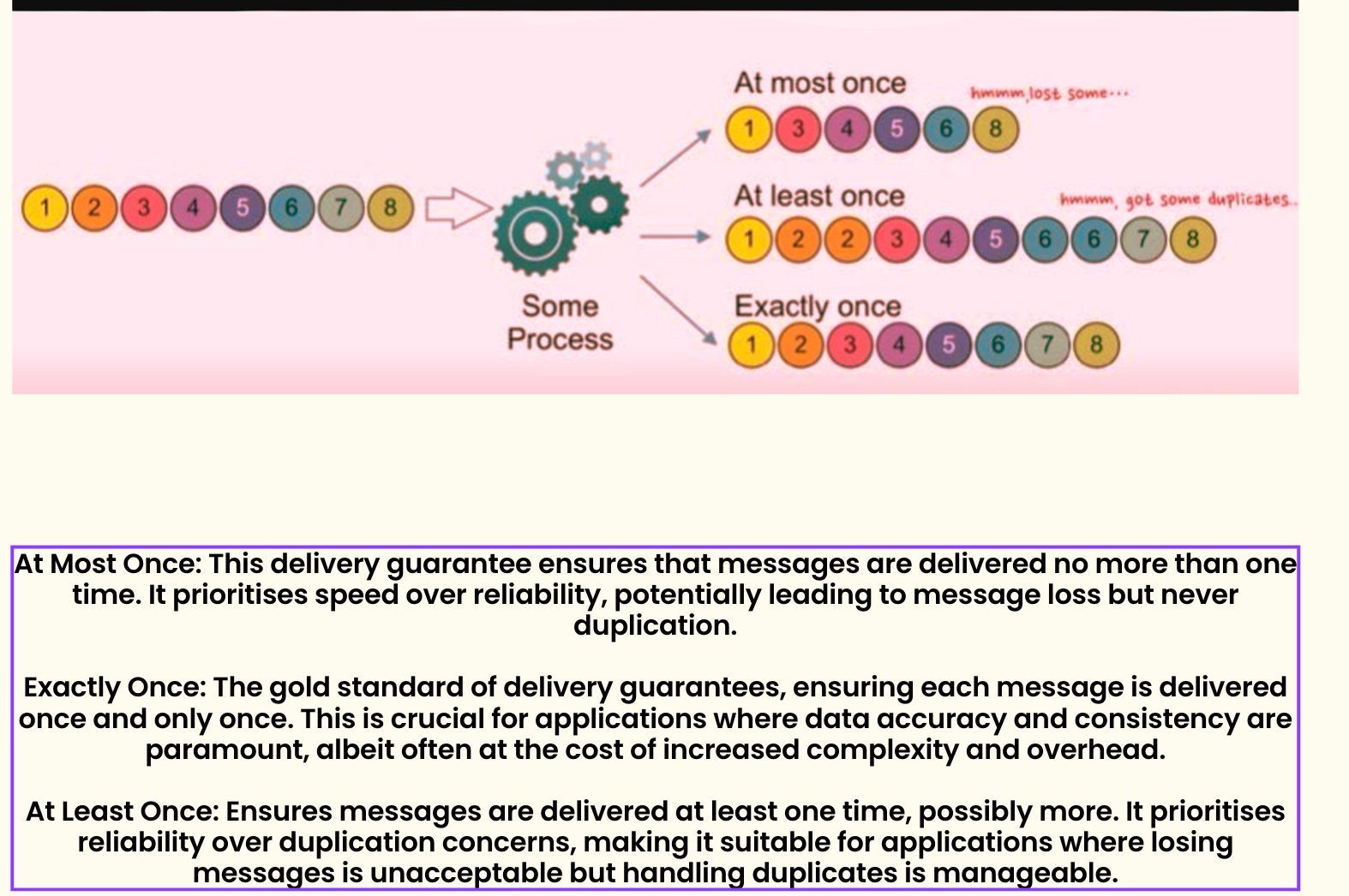
Offset Management:
Offsets are an essential part of Kafka’s operation. Each record in a partition is assigned a unique offset, which acts as an identifier for that record. Consumers use offsets to keep track of which records have been processed. Kafka allows consumers to commit offsets, enabling them to resume processing from the last committed offset in case of a failure.
Retention Policies:
Kafka provides flexible retention policies that dictate how long data is kept in a topic before being deleted or compacted. By default, Kafka retains data for a set period, after which it is automatically purged. However, Kafka also supports log compaction, where older records with the same key are compacted to keep only the latest version, saving space while preserving important data.
Compaction:
Log compaction is a Kafka feature that ensures that the latest state of a record is retained while older versions are deleted. This is particularly useful for use cases where only the most recent data is relevant, such as in maintaining the current state of a key-value store. Compaction happens asynchronously, allowing Kafka to handle high write loads while maintaining data efficiency.
4. Real-World Applications of Kafka
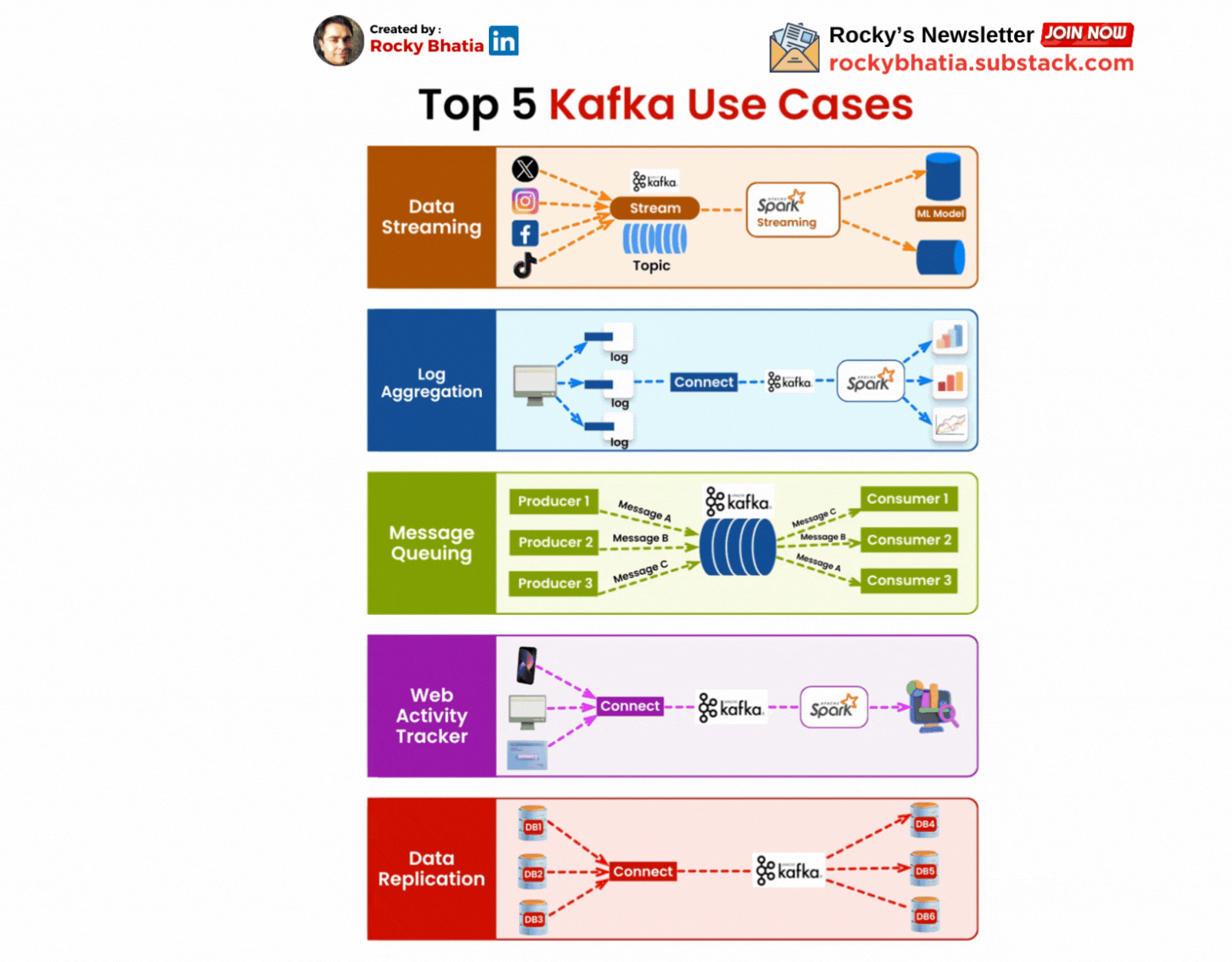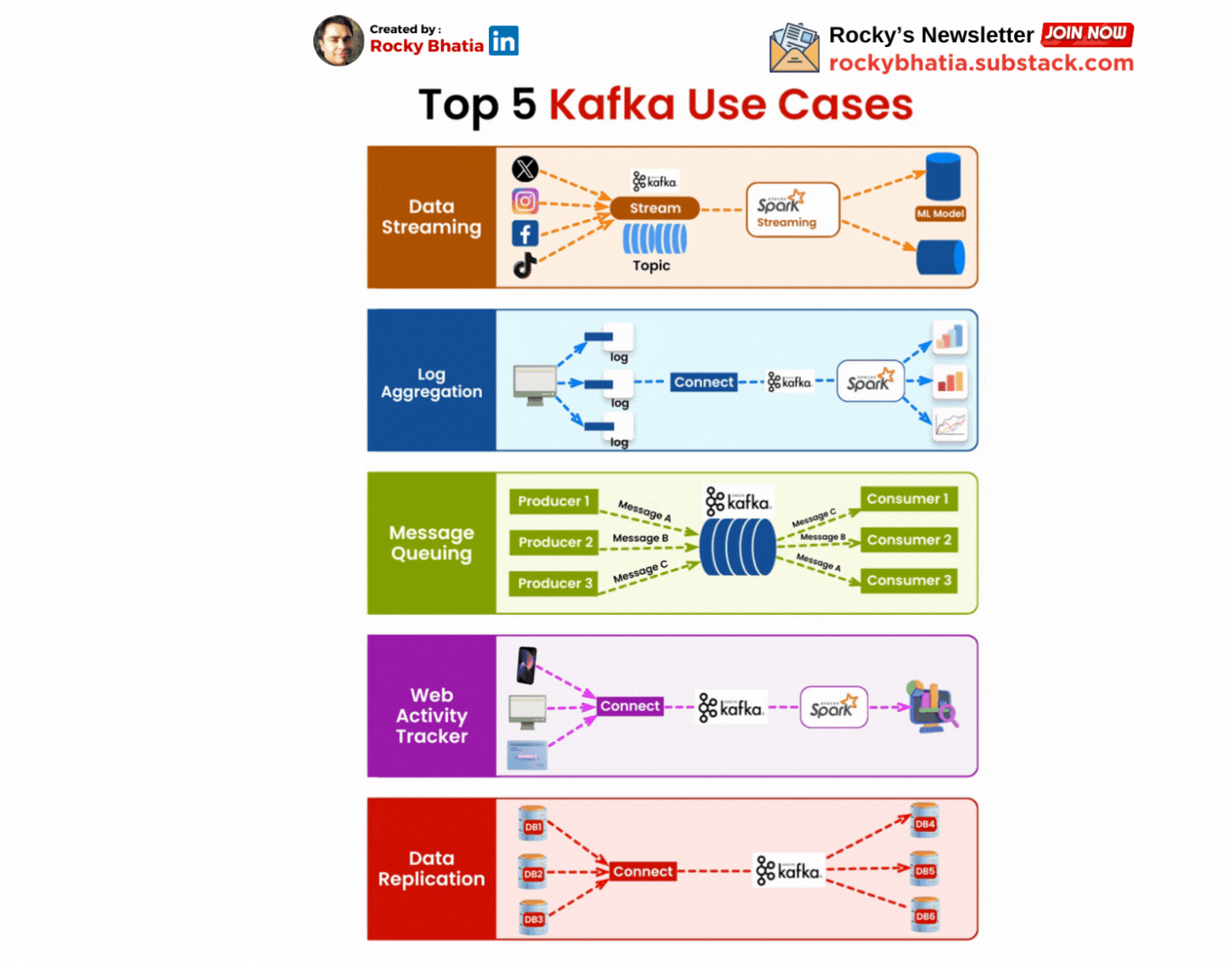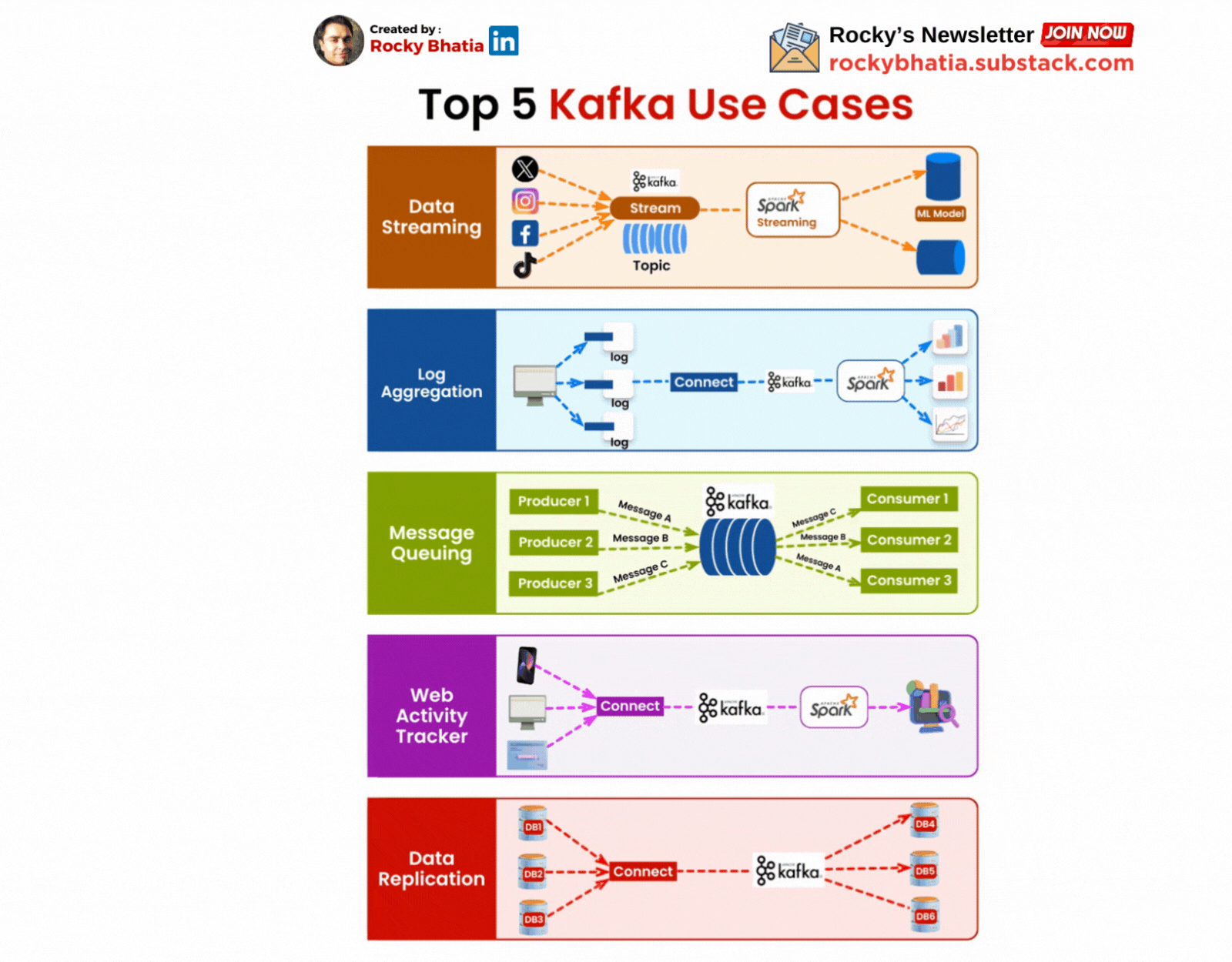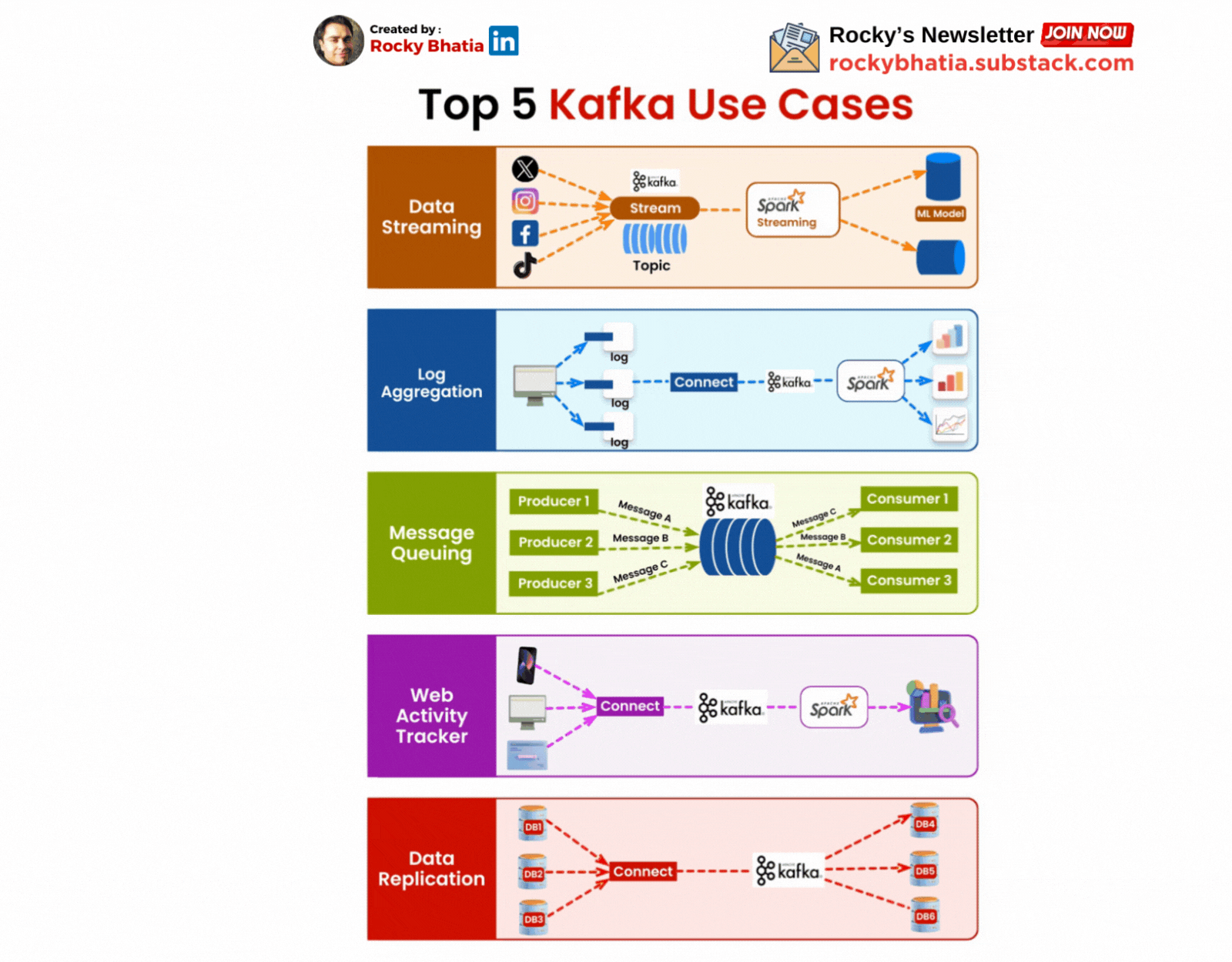
Real-Time Analytics:
One of Kafka’s most common use cases is in real-time analytics. Companies use Kafka to collect and analyse data as it’s generated, enabling them to react to events as they happen. For example, Kafka can be used to monitor server logs in real time, allowing teams to detect and respond to issues before they escalate.
Event Sourcing:
Kafka is also a powerful tool for event sourcing, a pattern where changes to the state of an application are logged as a series of events. This approach is beneficial for building applications that require a reliable audit trail. By using Kafka as an event store, developers can replay events to reconstruct the state of an application at any point in time.
Microservices Communication:
Kafka’s ability to handle high-throughput, low-latency communication makes it ideal for micro services architectures. Instead of services communicating directly with each other, they can publish and consume events through Kafka. This decoupling reduces dependencies and makes the system more resilient to failures.
Data Integration:
Kafka serves as a central hub for data integration, enabling seamless movement of data between different systems. Whether you’re ingesting data from databases, sensors, or other sources, Kafka can stream that data to data warehouses, machine learning models, or real-time dashboards. This capability is invaluable for building data-driven applications that require consistent and reliable data flow.
5. Kafka Connect
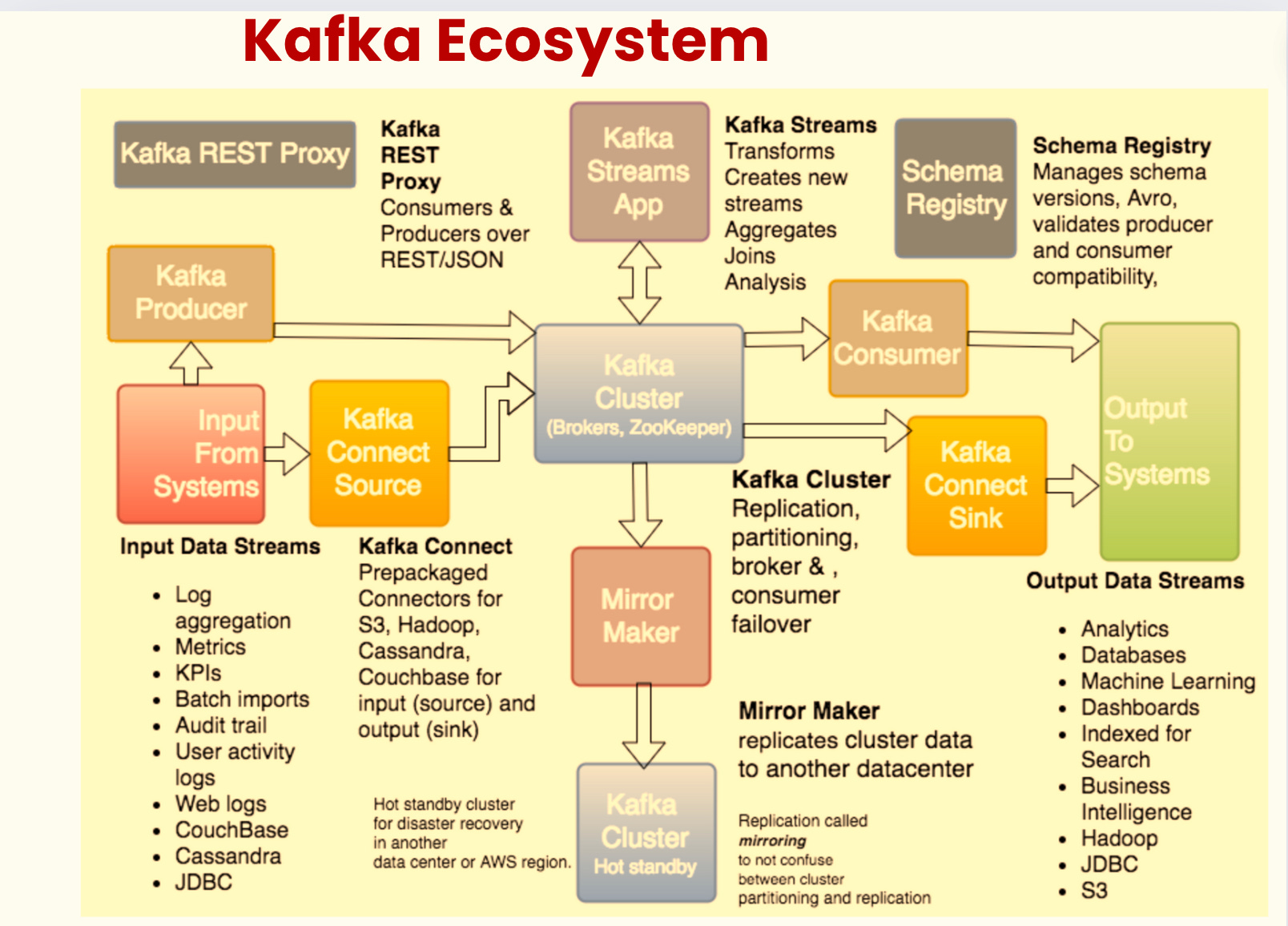
Data Integration Framework: Kafka Connect is a tool for streaming data between Kafka and external systems like databases, message queues, or file systems.
Source and Sink Connectors: It provides Source Connectors to pull data from systems into Kafka and Sink Connectors to push data from Kafka to external systems.
Scalability and Distributed: Kafka Connect is distributed and can be scaled across multiple workers, providing fault tolerance and high availability.
Schema Management: Kafka Connect supports schema management with Confluent Schema Registry, ensuring consistency in data formats across different systems.
Configuration Driven: Kafka Connect allows easy configuration of connectors through JSON or properties files, requiring minimal coding effort.
Single or Distributed Mode: Kafka Connect can run in standalone mode for small setups or distributed mode for larger, more complex environments.
Conclusion
By now, you should have a solid understanding of Kafka, from the basics to the intricacies of its architecture and internals. Kafka is a versatile tool that can be applied to various real-world scenarios, from real-time analytics to event-driven architectures. Whether you’re planning to integrate Kafka into your existing systems or build something entirely new, this crash course equips you with the knowledge to harness Kafka’s full potential.
Hope you enjoyed reading this article.
If you found it valuable, hit a like and consider subscribing for more such content every week.
If you have any questions or suggestions, leave a comment.
This post is public so feel free to share it.
Subscribe for free to receive new articles every week.
I actively post coding, system design and software engineering related content on
Spread the word and earn rewards!
If you enjoy my newsletter, share it with your friends and earn a one-on-one meeting with me when they subscribe. Let's grow the community together.
I hope you have a lovely day!
See you soon,
Rocky